
Google has announced an overhaul in its Crawler documentation, reducing its main page as well as splitting the material into three distinct pages that are more targeted. The changelog does not highlight the changes, there’s an entirely new section, which is basically a complete overhaul of the entire overview page. The more pages allow Google to improve the content density of every crawler page and increases the coverage of topics.

What Changed?
Google’s documentation changelog lists two changes, but there’s much more.
Here are a few of the modifications:
- The user agent has been updated to reflect the latest strings for GoogleProducer crawler
- The added material encoded information
- New section added about technical properties
The technical properties section has totally new information that didn’t previously existed. There is no change in the behavior of the crawler however, by creating three pages that are specifically targeted to the top, Google can now provide more information on the overview page of the crawler while also shrinking it.
The is newest information regarding material encoders (compression):
“Google’s searchers as well as fetchers can support the following material encryptions (compressions) including deflate, gzip, as well as Brotli (br). The material encoders used by every Google user agent are listed in the Accept-Encoding header for every demand they send. For example, Accept-Encoding: gzip, deflate, br.”
There’s extra details on crawling over HTTP/1.1 and HTTP/2, as well as the goal of their program is to crawl the most pages is possible without affecting the server of the website.
What Is The Goal Of The Revamp?
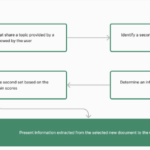
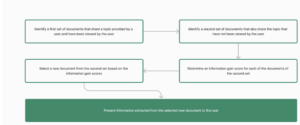
The changes in the document was the result of the fact that its overview was becoming huge. More information on crawlers could create the page bigger. It was decided to divide the page into three sections to warrant that the crawler’s specific material can continue to expand while allowing for generic information in the overview page. The idea of separating subtopics to separate pages is an excellent solution to the issue of how perfect to provide users with the perfect experience.
This is the way that the documentation changelog explains this changes:
“The documentation got extremely long, which hampered our ability to expand the material on our crawlers and fetchers that are triggered by users.
…Reorganized information for Google’s crawlers as well as fetchers that are triggered by users. We also added specific information about the products each crawler affects, as well as included the robots.txt short description for each crawler, to show how to use tokens for user agents. There were no significant modifications to the material or otherwise.”
The changelog tries to minimize the effects by calling them a restructuring of the crawler since the overview has been significantly revised and also the introduction of three brand-new pages.
Although the material is largely similar, the division of the topic into sub-topics makes it simpler to Google to add new material to new pages and not expand the page that was originally created. The original page, which was called”Overview that was created by Google searchers, fetchers (user agents) is now an overview, with more detailed material that has been moved to standalone pages.
Google released the following three pages on its new website:
- Common crawlers
- Special-case crawlers
- Fetchers with user-triggered triggers
1. Common Crawlers
As it says on the title, these are common crawlers, some of which are associated with GoogleBot, including the Google-InspectionTool, which uses the GoogleBot user agent. All the bots that are that are listed on this page follow their robots.txt rules.
This is the official Google crawlers.
- Googlebot
- Googlebot Image
- Googlebot Video
- Googlebot News
- Google StoreBot
- Google-InspectionTool
- GoogleOther
- GoogleOther-Image
- GoogleOther-Video
- Google-CloudVertexBot
- Google-Extended
3. Special-Case Crawlers
They are crawlers connected to particular products. They are accessed by a contract with the users of those products. They operate using IP addresses that differ to those of GoogleBot the crawler’s IP addresses.
List of Special-Case Crawlers:
- AdSenseUser Agent for Robots.txt: Mediapartners-Google
- AdsBot
User Agent for Robots.txt: AdsBot-Google - AdsBot Mobile Web
User Agent for Robots.txt: AdsBot-Google-Mobile - APIs-Google
User Agent for Robots.txt: APIs-Google - Google-Safety
User Agent for Robots.txt: Google-Safety
3. User-Triggered Fetchers
The User-triggered Fetchers page focuses on bots activated through the user’s request. It is explained as this:
“User-triggered fetchers” are initiated by users to carry out the fetching task within the Google product. For instance, Google Site Verifier acts upon a request from a user, or a site that is hosted in Google Cloud (GCP) has a feature that permits the users of the site to access from an external RSS feed. Because the request was initiated by a user fetchers typically do not adhere to robots.txt rules. The technical aspects of Google’s crawlers are also applicable to fetchers initiated by the user.”
The document refers to some of the bots listed below:
- Feedfetcher
- Google Publisher Center
- Google Read Aloud
- Google Site Verifier
Takeaway:
Google’s overview page for crawlers has become too extensive and may not be as efficient because people don’t usually require a large-scale page, they’re more looking for specific details. The overview page isn’t as specific, but it’s also simpler to comprehend. It serves as an entry point for users who can explore more specific topics that are in relation to the three kinds of crawlers.
This update provides insight into how to improve the page that is not performing well because it is overly complex. Separating a large page into distinct pages lets subtopics to cater to the specific needs of users and could improve their value should they be ranked in results of a search payoff.
I don’t think the change is a reflection of Google’s algorithm. It simply is a reflection of the way Google has updated the documentation of their site to be more helpful and also set it up to add more details.
Read Google’s New Documentation
A brief overview of Google crawlers and fetchers (user agents)
The Google crawlers that are most commonly used
A list of special-case crawlers from Google
A list of Google fetchers that are triggered by users
Featured Image by Shutterstock/Cast Of Thousands